동기화 시스템(echo system) 회고 5
동기화 시스템(echo system) 회고 1
동기화 시스템(echo system) 회고 2
동기화 시스템(echo system) 회고 3
동기화 시스템(echo system) 회고 4
동기화 시스템(echo system) 회고 5
동기화 시스템(echo system) 회고 6
문제점 2: 로그 동기화(?)에 대한 숙제
여기서 말하는 "로그"는 시스템이나, 어플리케이션 등에 대한 datadog이나 fargate등에 기록하는 로그가 아닌, 백오피스에서 동작한 "이벤트에 대한 로그"입니다. 즉, 상품이 A -> B로 변경되거나, 링크되어 있는 협력사 상품이 몇 개였는지, 어떤 카테고리로 이동했는지에 대한 로그입니다.
회사에서는 이런 로그들과 로그를 기반으로 생성된 통계를 바탕으로 다음년도의 사업을 예측하고 기획합니다. 필요한 부분에 더 많은 지원을 하고 부족한 부분을 강화하는 등 사업 영역에서는 꽤나 중요한 역할을 하는 부분에 해당합니다.
타서비스에서 다루는 거의 모든 프로세스는 이관이 되었습니다. 다만, 로그는 현재 프로세스와 다른 트랜잭션으로 백오피스에서 직접 저장해주고 있습니다. (눈치 빠르신 분들은 동기화 시스템 회고2에서 타 서비스 로직은 분리되었으나, 로그 작업은 분리되지 않은 것을 발견하실 수 있습니다.) 로그도 별도의 서비스로 생각하고, 분리하고 싶었습니다.
더 잘 쌓고, 유연하게 사용하고 싶었습니다.
당연하게도, 모든 토픽을 컨슈밍 하기만 한다면 모든 이벤트에 대한 로깅이 가능해집니다.
현재는 사용자 측에서 요청한 로그를 RDBMS에 직접 저장하고 있으며, 그 로깅 데이의 양이 점차 많아지고, 요청할 때마다 필요에 따라 데이터를 저장하다 보니, 중복되는 데이터가 많아졌습니다. 아울러 카운트나, 추출, 그리고 이관 시 연관관계 등 프로세스의 복잡도가 높아지고 새로운 로그를 추가하거나, 유연하게 사용하기가 어렵습니다.
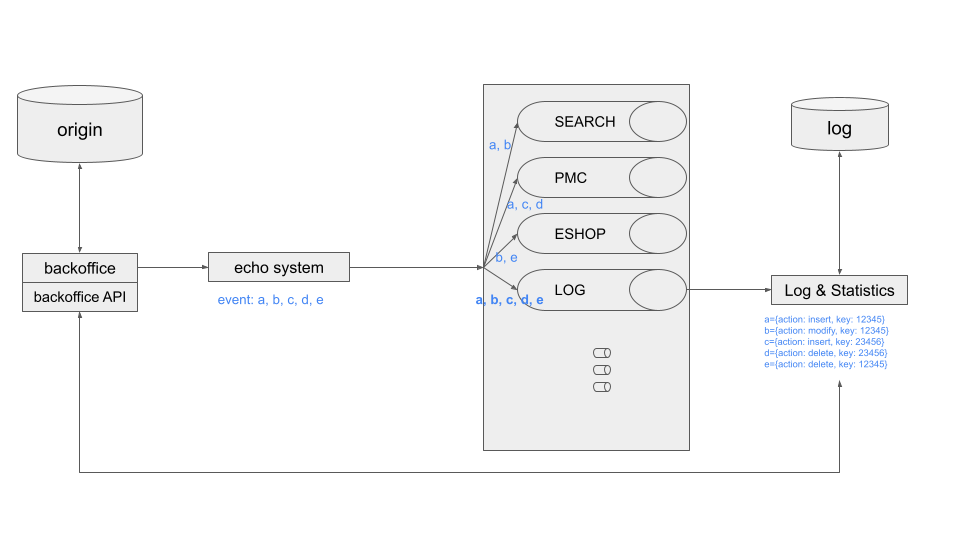
누적 로그가 억 단위를 돌파함에 따라 조회 역시 어려워졌습니다. 특정 조회 조건에 최적화해서 모델링을 했기 때문에, 조금이라도 그 범주에서 벗어나는 경우 groupby나 distinct는 물론, LIKE 조회가 거의 불가능해졌습니다. 사내 공용자원인 db 리소스를 너무 가져다 쓰고, 빈번한 슬로우 쿼리 발생, 이로 인한 서비스의 오류 및 장애는 눈앞에 닥친 현실이 되었습니다.
이를 개선하기 위해, 이벤트 기반으로 컨슈밍 된 전체 작업 로그를 document형태로 저장하고 그중 필요한 부분을 추출하여 통계나 2차 가공해서 가시적으로 보여주는 구조를 생각했습니다.
특정 작업을 기준으로 그 작업과 연관된 것들을(상품을 기준으로 최저가, 링크 수, 구매 클릭 등) 조회할 수 있으며, 그 작업과 연결된 또 다른 로그를 다각도로 알 수 있을 거라고 판단했습니다. (협력사 상품은 어떤 다나와 기준 상품에 링크가 되었다가 해제되었는지, 가격은 언제 어떻게 변경되었는지 등)
그것들을 통계 낸 값들은 스케줄을 통해 RDBMS에 저장하여 빠르게 보여주고, 원천 데이터는 Elastic search나 nosql 등을 통해 저장하고 색인하여, 빠르게 조회를 제공할 계획입니다.

다만, 이 경우 모든 로그를 기록하려면 프로듀서로 백오피스뿐만 아니라, 다른 내부 서비스(수집기, 분류기)는 물론 이 외 연관된 외부 서비스들이 추가되어야 할 수 있습니다. 이때는 현재의 메시징 처리구조에서 Kafka, 또는 AWS-SQS, GCP-Pub/Sub으로의 전환이 필수적으로 필요합니다.
현재 서비스에서 경우에 따라 최대 10억 건 이상의 데이터도 존재하기 때문에 해당 내용에 대한 개선방법을 검토 중이며, 메시지에 키값만 전달하고 있는 구조이므로, 삭제 후에 키를 전달하는 경우 해당 데이터를 API로 조회할 수 없기 때문에 별도의 처리가 필요합니다.
아래와 같은 내용을 검토중이며, 이후 개선 진행시 별도의 페이지로 기록 예정입니다.
1. 해당 데이터를 온전히 로그 서비스에 동기화해서 처리하는 구조
2. kafka-connector와 kafka를 통해 각자의 서비스에서 데이터를 핸들링하고, 데이터를 삭제하지 않고 태그로 상태를 기록하는 구조
동기화 시스템(echo system) 회고6으로 이어집니다.